

První tabulka
V této kapitole se konečně naučíte pracovat s tabulkami. Naučíte se tabulku vytvořit, vložit do ní nějaká data, zobrazit si je a nakonec tabulku zase smazat. Po této kapitole už budete téměř schopni databáze využívat v reálném životě.
Datové typy
Pokud chcete vytvořit tabulku, musíte databázi (DBMS) říct, jaká data budete do
sloupců tabulky ukládat (například jestli to bude text nebo číslo).
To umožňuje DBMS s tabulkami snadno pracovat. Jednak je hned jasné, které
operace s hodnotami v daném sloupci lze provádět (čísla lze
násobit, text ne) a také umožňuje snadnou správu databáze, neboť je
(většinou) předem jasné, kolik bude zabírat jeden řádek tabulky místa na
disku.
K tomu, abyste určili jaká data budete do sloupců ukládat,
slouží datové typy. Datový typ určuje jednak jaký typ dat budete
ukládat (text, celé číslo, číslo s desetinou čárkou) a také kolik
bytů bude zabírat. Například typ integer je celé číslo 4 byty
dlouhé, jeho rozsah je cca -2 až 2 miliardy, smalint je celé číslo 2 byty
dlouhé, jeho rozsah je cca -32 až 32 tisíc, atd.).
V následující tabulce vidíte nejpoužívanější datové typy z PostgreSQL.
Pokud vás zajímají další, použijte metapříkaz \dTS.
Datové typy je jedna z věcí, ve kterých se DBMS od sebe dost liší (a stěžují tak přenositelnost
mezi databázemi). DBMS mají pár datových typů společných
(například integer nebo text, date), ale i ty se mohou lišit například
v tom, kolik bytů jsou dlouhé, jak se v nich hodnoty ukládají (například datum může být ukládán s nebo bez časové zóny).
Když budete přecházet z jednoho DBMS do druhého, raději si pořádně datové typy nastudujte.
| Typ | Význam | Popis |
|---|---|---|
| boolean | Logická hodnota | Může nabývat pouze dvou hodnot: true (pravda) a
false (nepravda). Za true se též považuje každá nenulová hodnota, za false pak nulová hodnota. V některých DBMS je bool jen synonymem pro celé číslo
dlouhé 1 bit, tj může obsahovat jen jedničku (pravdu) nebo nulu (nepravdu).
|
| char(n) | Znakový řetězec | Délka řetězce je n znaků. Zadáte-li kratší řetězec, bude
doplněn z prava mezerami. Za n se dosazuje celé kladné číslo. Všechny typy znakových řetězců se v SQL příkazech uvozují jednoduchými 'uvozovkami'. Pokud je jednoduchá uvozovka součástí řetězce, musí se před ní napsat zpětné lomítko: \'. Hodí se na řetězce o kterých předem víte, že budou mít (více méně) vždy stejnou délku (například sloupeček rodných čísel). |
| varchar(n) | Znakový řetězec | Délka řetězce může být maximálně n znaků. Zůstává ve své délce (nedoplňuje se mezerami). Varchar obsahuje informaci o délce řetězce (krom samotného řetězce). Práce s ním je o fous pomalejší, ale zabírá méně místa než char,
navíc se nedoplňuje mezerami, takže varchar se používá mnohem
častěji než char.
|
| text | Znakový řetězec | Řetězec (skoro) neomezené délky. Pokud nemusíte, nepoužívejte.
Zpomaluje práci s daty v databázi. Hodí se na všechny texty, kde nechcete nebo nemůžete omezit délku (například na ukládání textu článků). |
| integer | Celé číslo | Číslo bez desetinné čárky. Přípustné hodnoty jsou cca od -2 do 2 miliard. |
| float | Reálné číslo |
Číslo s desetinnou čárkou. (Spíše bych měl napsat s desetinnou
tečkou.)float má omezenou přesnost (občas zapomíná poslední
desetinná čísla atp.). Naprosto se nehodí na ukládání informací
o penězích!
|
| numeric(p,d) | Reálné číslo | Číslo se zadanou přesností. Parametr p určuje celou
délku čísla, parametr d kolik z toho bude za desetinnou
čárkou. Například za numeric(5, 3) můžete dosadit maximálně
[+/-]99.999.numeric v rámci svého rozsahu uloží čísla vždy „přesně“,
hodí se proto na ukládání informací o penězích. Na druhou stranu zabírá více
paměti než float.
|
| serial * | Automatické (celé) číslo | Do sloupce s tímto typem se automaticky ukládá nepoužité číslo. Začíná se od 1, pokračuje 2, 3, 4 atd. (není li určeno jinak). Hodí se jako primární klíč. Více o serial. |
| date | Datum | Zadává se jako textový řetězec ve tvaru '2002-09-26'. |
| time | Čas | Zadává se jako textový řetězec ve tvaru '13:00:13.440270'
(Přesnost na milióntinu vteřiny), nebo jen '13:00:00'
(hodiny, minuty, vteřiny) nebo jen 'hodiny:minuty'. Jakým způsobem se odděluje čas (jestli dvojtečkou, nebo tečkou) se dá v PostgreSQL nastavit příkazem SET datestyle,
ale to je zatím nad rámec tohoto tutoriálu.
|
| timestamp | Čas + datum | '2002-09-26 13:07:40' |
* U typu SERIAL se ještě
trochu pozastavím. Pokud jej v nějakém sloupci použijete, pro jeho
správnou funkci se vytvoří v databázi objekt
sekvence. Všechny sekvence v databázi (tedy vlastně schématu)
můžete vypsat pomocí metapříkazu \ds.
Po zrušení tabulky obsahující datový
typ SERIAL je třeba zrušit i tuto sekvenci a to příkazem
PostgreSQL už maže sekvenci automaticky. Nicméně se pořád může stát, že budete mít
v databázi nějaké neopoužité sekvence. O tom ale až jindy.
DROP SEQUENCE nazev_sekvence.
Název sekvence se generuje automaticky a to ve tvaru
nazevtabulky_nazevsloupce_seq.
Podrobnosti o sekvencích popíši později v CREATE SEQUENCE.
Některé datové typy mají své zkratky, takže například místo boolean můžete
psát bool, nebo místo integer jen int.
PostgreSQL je slavný tím, že má velkou škálu datových typů. Najdete v něm datový typ pro kruh, obdélník, polygon, IP adresu, MAC adresu, XML, JSON a mnoho dalších zajímavostí. Určitě se koukněte na datové typy do dokumentace.
Práce s tabulkou
Teď je ten správný čas vrhnout se na vytváření tabulek. Zde probírané příkazy budou v dalších kapitolách probírány podrobněji, nyní se naučíte jen nezbytné minimum z SQL příkazů.
Při psaní SQL příkazů nezáleží na velikostech písmen, nicméně pro přehlednost budu psát nezaměnitelné výrazy velkými písmeny, výrazy za které si dosazujete svoje jména (tabulek, sloupců…) malými.
CREATE TABLE – vytvoření tabulky
Příkaz CREATE TABLE slouží k vytvoření tabulky. Za klíčovými slovy
CREATE TABLE následuje jméno vytvářené tabulky a v závorce jména
sloupců následovaná datovým typem sloupce. Jména a datové typy
jednotlivých sloupců se oddělují čárkou.
rimmer1(> prijmeni VARCHAR(20),telefon VARCHAR(20));
CREATE
Příkazy SQL se v Postgresu ukončují středníkem. První řádek jsem
ukončil stiskem klávesy ENTER. Všimněte si, jak se změnil prompt.
Místo rovnítka je tam kulatá závorka, která nás upozorňuje na to,
že jsme v některém z předchozích řádků začali se závorkou a měli
bychom jí ukončit.
Telefon, ač se to může zdát býti čislo, jsem určil jako datový typ VARCHAR,
neboť s telefonem nebudu provádět žádné matematické operace
(sčítání telefonů není moc užitečné). Tím se můžu vyvarovat někdy v
budoucnu chyb, protože kdybych se pokusil telefony sčítat, Postgres
ohlásí chybu "sčítání řetězců". A taky nebudu mít problém s telefonem, který
začíná nulou.
Poslední věc o které bych se měl zmínit je hlášení, které se vám vypíše po provedení SQL příkazu. V tomto případě vidíte hlášení CREATE, které vám oznamuje, že tabulka byla vytvořena. V případě že se jí nepodaří vytvořit vypíše se chybové hlášení s popisem chyby, která neumožnila příkaz provést (podobná hlášení obdržíte i od ostatních příkazů SQL). Zkuste třeba znovu vytvořit tabulku telefonni_seznam (šipkou nahoru se „vyrolujete“ k příkazu CREATE TABLE).
rimmer1(> prijmeni VARCHAR(20),telefon VARCHAR(20));
ERROR: relation 'telefonni_seznam' already exists
Nelekejte se, error není konec světa. Tabulka telefonni_seznam, která již existovala, existuje dál a stále obsahuje všechny hodnoty, které jste do ní vložily (Zatím jste nevložili žádné :-)).
O existenci tabulky se můžete přesvědčit metapříkazem \d.
Seznam relací
Schéma | Jméno | Typ | Vlastník
--------+-----------------+---------+----------
public | pokus | tabulka | petr
public | telefonni_seznam | tabulka | petr
(1 řádka)
rimmer1=> \d telefonni_seznam
Tabulka "public.telefonni_seznam"
Sloupec | Typ | Modifikátory
----------+-----------------------+--------------
jmeno | character varying(20) |
prijmeni | character varying(20) |
telefon | character varying(20) |
Nenechte se zmást tím, že je tabulka v schématu „public“, ikdyž jste jí vytvořili
v schématu rimmer1. Jak se se schématy v PostgreSQL pracuje se dozvíte někdy později.
Nenechte se ani zmást typem sloupce character varying(20). Datový typ
VARCHAR je zkratka pro character varying. Pro integer existuje
zase zkratka int atp.
Postgres nemá SQL příkaz ani metapříkaz pro zobrazní CREATE TABLE statementu, kterým by
se dala tabulka znova vytvořit (třeba v jiném schématu). Můžete ale použít program pg_dump.
Výstup se může lišit od vašecho původního CREATE TABLE statementu, ze stejných důvodů, jak je pospáno níže u MySQL příkazu SHOW CREATE TABLE.
INSERT – vložení dat do tabulky
Příkaz INSERT slouží ke vkládání řádků do tabulky. Za klíčovými
slovy INSERT INTO následuje název tabulky, klíčové slovo VALUES
a seznam hodnot oddělených čárkou.
Hodnota NULL
Pokud do některého sloupce nechcete vložit hodnotu,
můžete použít speciální hodnotu NULL.
Tato hodnota se může použít za libovolný
datový typ a říká, že položka „nemá žádnou zadanou hodnotu, resp. že
její hodnotu neznám“.
Hodnota NULL se ničemu nerovná. Pokud jí třeba použijete v sloupečku
s datovým typem integer, pak NULL rozhodně není totéž jako 0 (nula je totiž hodnotou)!
Hodnota NULL není ani větší ani menší než jakákoliv jiná hodnota
(tj. podmínka promenna > NULL bude vyhodnocena jako
false (nepravda), stejně tak i promenna < NULL je false).
Taky platí, že NULL se nerovná NULL. Hodnotu NULL
můžete brát jako „nevím co tam je“. A když nevíte, nemůžete ani tvrdit, že
se hodnoty rovnají.
INSERT 0 1
rimmer1=> INSERT INTO telefonni_seznam VALUES(NULL, 'Satan', '333999666');
INSERT 0 1
Pokud budete mít hodně sloupců a budete chtít vytvořit řádek s
hodnotami jen v některých sloupcích, můžete vyjmenovat jména
sloupců, do kterých dosazujete, za jménem tabulky v závorce
oddělené čárkou.
Sloupce do kterých nic nevložíte budou mít
defaultní hodnotou, která je NULL (časem ukážu,
jak můžete defaultní hodnotu změnit na něco smysluplnějšího).
rimmer1-> VALUES ('Lucifer', '22222223');
INSERT 0 1
Čísla vřádce INSERT 0 1, která se zobrazí po vložení řádku, zobrauzují nějaké OID (identifikátor objektu. Pokud ho postgres nepoužije, zobrazí se 0. Jako v příkladu.) a počet vložených řáků.
SELECT – výběr dat z baulky
Příkaz SELECT je jeden z nejpropracovanějších příkazů SQL. Slouží k
vybrání řádků a sloupců z tabulky a mnoha mnohda dalším věcem. Zatím vám
bude stačit vědět, jak vybrat celou tabulku, abyste se mohli
podívat na to, co v tabulce máte.
jmeno | prijmeni | telefon
-------+----------+-----------
Santa | Klaus | 333222111
| Satan | 333999666
| Lucifer | 22222223
(3 řádky)
NULL, nebo jestli je tam prázdný řetězec ''.
Jste-li nedočkaví, můžete se nyní mrknout na kapitoly o příkazu SELECT SELECT a SELECT II. K těmto kapitolám se dostanete později, až získáte další potřebné znalosti.
DROP TABLE – smazání tabulky
Podívejte se, co vám o příkazu DROP TABLE řekne nápověda Postgresu
vyvolaná pomocí metapříkazu \h.
Příkaz: DROP TABLE
Popis: odstraní tabulku
Syntaxe:
DROP TABLE [ IF EXISTS ] jméno [, ...] [ CASCADE | RESTRICT ]
Nebylo těžké uhodnout, že příkaz DROP TABLE slouží ke zrušení tabulky.
Pokud tabulku zrušíte, přijdete nenávratně i o všechny data v ní! Syntaxe
je taková, že nejdříve napíšete klíčová slova DROP TABLE, potom
jméno tabulky, popřípadě další jména tabulek určených ke zrušení
oddělených od sebe čárkou.
DROP
MySQL/MariaDB
MySQL má také datové typy char, varchar, text,
mediumtext, longtext, integer, float, numeric a date.
Bool je jen synonymum pro integer(1) (číslo dlouhé 1 bit – může obsahovat jen
jedničku nebo nulu). Nemá serial
(K tomuto „typu“ se ještě vrátím v některé další kapitole. Teď jen prozradím, že MySQL nemá sekvence.)
Místo timestamp má datetime. Má i timestamp, ale ten se chová trochu speciálně. Práce s časy a datumy je vůbec
v SQL databázích zajímavý oříšek, takže se tomu budu věnovat později v samostatné kapitole.
MySQL má samozřejmě i další datové typy
(stejně tak MariaDB).
Sice ne ty, co jsem vyjmenovával extra u PostgreSQL, ale třeba má navíc set nebo enum.
Pokud chcete přenést tabulku z jednoho DBMS do druhého, vždy se ujistěte, že existují stejné datové typy a že se i chovají stejně (mají stejný rozsach hodnot, stejnou defaultní hodnotu, chovají se stejně při sčítání atp.).
Pokud se v PostgreSQL nebo Oracle pokusíte uložit do textového typu delší řetěcec než je povoleno (třeba do typu
varchar(10) 11 znaků dlouhý řetězec), způsobí to chybu a SQL příkaz se neprovede (nic se
nevloží). V MySQL se naproti tomu řetězec zkrátí a SQL příkaz se provede. (Vypíše se jen jakési
varování.)
Příklady použítí SQL příkazů z této kapitoly jsou pro MySQL stejné. To neznamená, že by všechny u všech zmíněných SQL příkazů neexistovali rozdíly. Jen jsem vám ty rozdíly prozatím zamlčel. Zmínim se teď jen o jednom a to u CREATE TABLE.
CREATE TABLE může v MySQL určit defaultní CHARSET a COLLATE pro tabulku. (Pokud jej
neurčíte, převezmou se defaultní hodnoty ze schématu).
Všimněte si, že je CHARSET (i COLLATE) zase DEFAULT. MySQL totiž umožňuje nastavit znakovou sadu i způsob třídění na úrovni sloupečku!
MySQL v Linuxu rozlišuje velikost písmen u názvu tabulky!
MySQL totiž používá název tabulky pro název souboru, ve kterém je tabulka uložená.
A protože Linux rozlišuje velikost písmen v názvech soborů (na rozdíl od Windows),
tak i v MySQL (v Linuxu) záleží název tabulky na velikosti písmen.
Je to hnus, ale co s tím naděláte. Doporučuji používat pro názvy tabulek vždy jen malá písmena.
V MySQL není metapříkaz \d pro zobrazení tabulek,
ale má na to speciální (nestandardní) SQL příkaz SHOW.
Na zobrazení popisu tabulky zase používá DESCRIBE.
+-------------------+
| Tables_in_rimmer1 |
+-------------------+
| telefonni_seznam |
+-------------------+
1 row in set (0.00 sec)
mysql> DESCRIBE telefonni_seznam;
+----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+-------+
| jmeno | varchar(20) | YES | | NULL | |
| prijmeni | varchar(20) | YES | | NULL | |
| telefon | varchar(20) | YES | | NULL | |
+----------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
Na zobrazení CREATE TABLE příkazu, kterým by se tabulka
dala znovu vytvořit, slouží příkaz SHOW CREATE TABLE.
Výstup tohoto příkazu nezobrazí váš původní SQL příkaz CREATE TABLE, ale sestaví jej na základě všech informací, které o tabulce DBMS má. Z toho důvodu výstup obsauje více informací, než jste při vytváření tabulky zadávali (přidá do CREATE TABLE explicitně i věci, které se vytvořili defaultně, protože jste je neuvedli), případně jsou zapsány jiným (ekvivalentním) způsobem.
SQLite
I SQLite má seznam svých datových typů (integer, real, text a blob). Je to o něco chudčí než v ostatních databázích, ale, vzhledem k tomu, že SQLite není určeno na nějaké velké složité databáze, určitě dostatečné.
Typ boolean je synonymum pro integer, podobně jako u MySQL, jen sqlite neumí omezit délku na 1 bit, takže
můžete do sloupečku „boolean“ vložit jakékoliv číslo. Na rozdíl od Postgresu a MySQL nezná
SQLite ani hodnoty true a false, takže můžete pro bool hodnoty používat jen jedničky a nuly.
SQLite má například jen jeden datový typ pro text a to text. Přesto vám umožní definovat sloupce
s datovými typy jako varchar(25) nebo char(10). Nicméně, takový sloupeček bude
fungovat jako text, tj. nezkrátí se na zadanou maximální délku pokud je moc dlouhý,
nedoplní se mezerami …
Příklady použítí SQL příkazů z této kapitoly jsou pro SQLite stejné, snad jen s tím rozdílem,
že DROP TABLE neumí smazat 2 tabulky najednou.
Metapříkaz pro vypsání všech tabulek je .tables a pro vypsání
CREATE TABLE statementu je .schema tablename.
Pozor! Za tablename nedávejte středník. SQLite by nevyhodil žádnou chybu, ale ani
by nezobrazil CREATE TABLE statement.
Oracle
I Oracle má své datové typy.
Místo varchar byste měli používat varchar2 (tahle podivnost je tam z historických důvodů). Místo numeric(n,m)
používá Oracle number(n,m) (numeric je ale funkční synonymum pro number).
Oracle nemá datový typ „serial“, ačkoliv používá pro primární klíče sekvence, podobně jako PostgreSQL.
Typ DATE uchovává jak datum tak i čas (na vteřiny), type TIMESTAMP navíc ukládá zlomky sekund.
Žádný datový typ, který by uchovával pouze datum nebo pouze čas není.
Místo text má Oracle clob (do
kterého se vejdou 4 GiB textu).
Mimo další základní datové typy, jako je integer či
float má i speciality jako třeba xml atp.
Datový typ boolean Oracle nezná ani jako synonymum, takže asi nepřekvapí, že nezná
ani true a false. Místo boolean můžete používat integer,
nebo třeba char, který omezíte integritním omezením CHECK jen na znaky 't' a 'f'.
Pokud použijete integer, můžete jej omezit pomocí CHECK na hodnoty 0 a 1.
Fantazii se meze nekladou. O podmínce CHECK bude řeč později, zatím ji můžete s klidným svědomím vynechat.
PS: Totéž platí i pro SQLite.
SQL příkazy z příkladů pro Postgres budou v Oracle fungovat beze změny (jen místo VARCHAR používejte VARCHAR2).
V Oracle je největší legrace s daty. Defaultní formát pro oracle vypadá tatko: '13-NOV-92' je 13 listopad 1992
a '23-NOV-13' je 23 listopad 2013. Oracle očekává, že mu budete dávat data v tomto formátu. To není úplně
nejšikovnější. Očekávaný formát se dá navíc přenastavit a bývá přenastaven podle lokalizace vašeho operačního systému.
Jistější je proto používat funkce TO_DATE a TO_CHAR (vždy).
INSERT INTO test VALUES (1, '13-NOV-92', '13 listopad 1992');
ORA-01843: not a valid month
INSERT INTO test VALUES (1, TO_DATE('1992-11-13','YYYY-MM-DD'), '13 listopad 1992');
SELECT * FROM test;
ID DATUM POZNAMKA
---------- ---------- --------------------
1 11/13/1992 13 listopdad 1992
INSERT INTO test VALUES (2, '11/23/2013', '23 listopad 2013');
SELECT id, TO_CHAR(datum,'YYYY-MM-dd HH24:MI:SS'), poznamka FROM test;
ID TO_CHAR(DATUM,'YYYY POZNAMKA
--------- ------------------- --------------------
2 2013-11-23 00:00:00 23 listopad 2013
1 1992-11-13 00:00:00 13 listopad 1992
Určitě jste si u posledního SELECTu v příkladu všimli, že jsem místo hvězdičky vyjmenoval sloupečky, které chci zobrazit. A dokonce jsem použil na jeden sloupeček funkci. To jste se zase naučili něco nového :-). Takto si můžete vybrat jen ty sloupečky které chcete vidět, můžete je vypsat v různém pořadí, aplikovat nějaké funkce (jako tady TO_CHAR) a ještě spoustu dalšího toho můžete. Ale o tom všem až v některé z dalších kapitol.
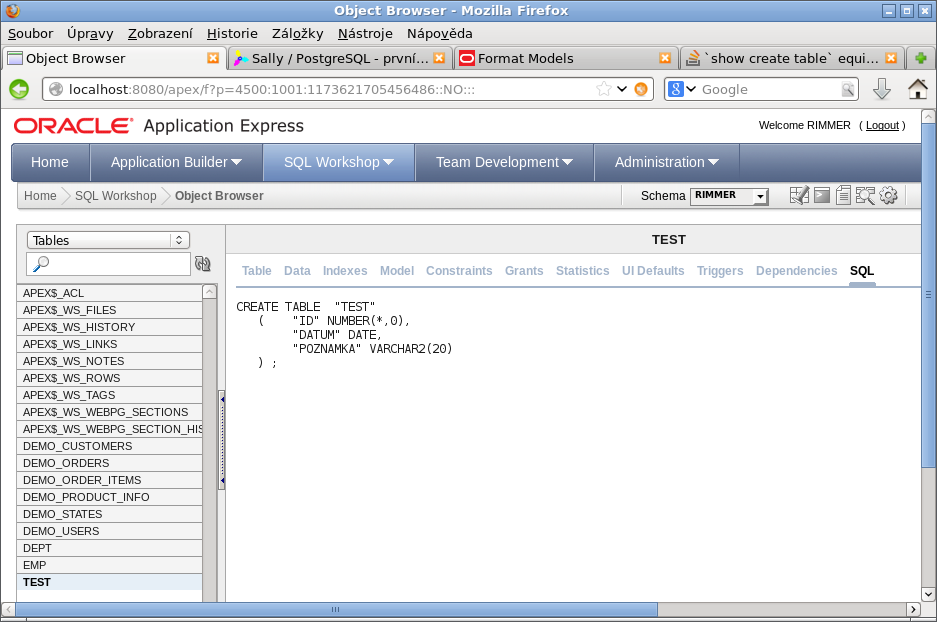
Apex – Object Browser
Pokud si budete chtít prohlédnout tabulky v databázi, jak tabulka vypadá a CREATE TABLE
statement pro tabulku, všechno to najdete v apexu pod záložkou SQL Workshop → Object Browser.
Budete tam mít už spoustu předdefinovaných tabulek, tak se nelekněte :-).
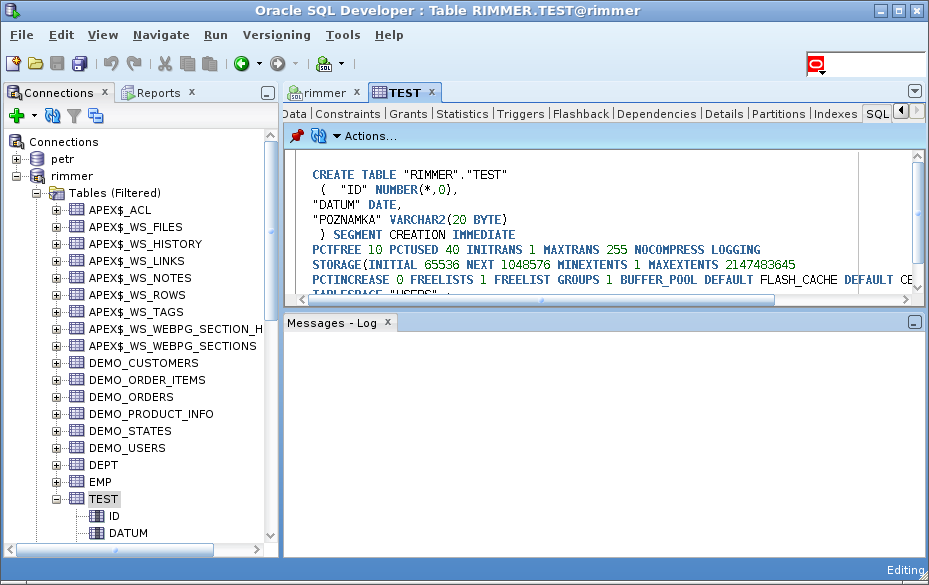
Oracle SQL Developer
Najít si seznam tabulek a jejich detail v Oracle SQL Developeru máte za domácí úkol. (Nápověda: použijte dvojklik).
PS: SQL dotaz pro získání seznamu všech dostupných tabulek je následující (zobrazí se i různé systémové tabulky, takže těch tabulek bude hodně):
Všiměte si, že jméno uživatele (RIMMER) je velkými písmeny.
