

Sekvecne a indexy
V této kapitole se dozvíte něco praktického o databázovém objektu sequence a o ještě důležitějších databázových objektech – indexech. O indexech byla již řeč v kapitole o integritních omezeních, takže teď je ta správná chvíle si zopakovat jejich význam.
Sekvence
O sekvencích jsem psal při popisování typu SERIAL. Jde o databázový objekt, který vám generuje nějakou posloupnost čísel.
Jméno sekvence je většinou tvořeno jménem tabulky, podtržítkem, jmenénem sloupce, podtržítkem a slovem seq. Takto se jména sekvencí tvoří při vytváření tabulky automaticky. Je to docela chytré, protože může existovat jen jedna tabulka stejného jména a v ní jen jeden sloupec stejného jména, nikdy nedojde ke kolizi jmen. Pokud vytváříte sekvneci sami, můžeme jí dát jméno téměř libovolné (bez mezer, české diakritiky atp.).
Vytvářet sekvneci se hodí například ve chvíli, kdy chcete z typu INTGETER vytvořit typ SERIAL (pokud vytváříte tabulku se sloupcem typu SERIAL rovnou, vytvoří se sekvence automaticky). Taky se to hodí, když chcete používat jednu sekvenci pro více tabulek (třeba když chcete mít jednu sekvenci primárních klíčů pro všechny tabulky v databázi. Někdo to tak má rád, protože pak jen podle ID poznáte libovolný záznam ze všech tabulek).
A teď rovnou k příkladu:
V příkladu jsem schválně vytvořil nejdřív sekvenci, aby bylo jasné, že je to objekt, který není nijak s tabulkou či sloupcem svázán. Proto si musíte dát pozor při rušení tabulky, která nějakou sekvneci využívá, abyste z databáze smazali i sekvenci (pokud jí teda už nebudete potřebovat), Jinak vám bude v databází zůstávat „smetí“.
Zkuste si vytvořit tabulku s typem SERIAL, poté tabulku zrušit
(sekvneci ponechat) a stejným příkazem jako poprvé tabulku
vytvořit. Kvůli existující sekvneci se to nepodaří.
To co jsem psal v předchozím odstavci už neplatí. Automaticky vytvořené sekvence při vytvoření tabulky se už při smazání tabulky automaticky mažou (v nových verzích Postgresu).
Podívejte se, co se stane, když přiřadíte sekvenci dvěma sloupcům. (Změna defaultní hodnoty viz další kapitola ALTER TABLE - DEFAULT).
ALTER
rimmer1=> ALTER TABLE mutant ALTER c2 SET DEFAULT nextval('mutant_c_seq');
ALTER
rimmer1=> INSERT INTO mutant VALUES ('jedna');
INSERT 17065 1
rimmer1=> INSERT INTO mutant VALUES ('dva');
INSERT 17066 1
rimmer1=> INSERT INTO mutant VALUES ('tri');
INSERT 17067 1
rimmer1=> SELECT * FROM mutant;
slovo | c1 | c2
-------+----+----
jedna | 1 | 2
dva | 3 | 4
tri | 5 | 6
(3 rows)
Jak vidíte, při insertování jsem využil defaultních hodnot pro sloupce c1 a c2.
Chtěl bych jen tak na okraj podotknout, že to nezaručuje unikátní hodnoty pro oba sloupce, jak by se mohlo zdát. Unikátní hodnoty zajišťuje jen podmínka UNIQUE, která dokáže zajistit unikátnost jen pro jeden sloupec (nebo kombinaci sloupců), ale ne unikátnost hodnoty v rámci více sloupců (tj. aby se číslo mohlo objevit pouze jednou v rámci obou sloupců).
Při vytváření sekvence můžete nastavit její minimální hodnotu
(implicitně 1), maximální hodnotu (implicitně maximální hodnota
typu INTEGER) krok (increment), tj. o kolik se bude další hodnota zvyšovat
(implicitně 1), počáteční hodnotu (implicitně 1) či zda se má sekvence
cyklit (pokud dojde na konec sekvence – k maximální hodnotě,
jestli má začít vracet čísla od začátku, nebo chybu).
Jak se to udělá snadno vyčtete z nápovědy,
nebo se můžete podítat na online nápovědu k CREATE SEQUENCE.
CREATE SEQUENCE
rimmer1=> SELECT nextval('test_cycle_seq'), nextval('test_cycle_seq'),
nextval('test_cycle_seq'), nextval('test_cycle_seq');
nextval | nextval | nextval | nextval
---------+---------+---------+---------
6 | 7 | 5 | 6
(1 řádka)
Smazání sekvence
Sekvnece se zruší pomocí DROP SEQUENCE. Můžete smazat pouze takovou sekvenci, která není využívána žádnou tabulkou.
ERROR: cannot drop sequence mutant_c_seq because other objects depend on it
DETAIL: default for table mutant column c2 depends on sequence mutant_c_seq
DOPORUČENÍ: Use DROP ... CASCADE to drop the dependent objects too.
rimmer1=> DROP TABLE mutant;
DROP TABLE
rimmer1=> DROP SEQUENCE mutant_c_seq;
DROP SEQUENCE
Funkce
Funkce nextval není jediná funkce, kterou můžete na sekvenci aplikovat.
Existuje ještě pár dalších funkcí, které například umožní nastavit aktuální hodnotu
sekvence. Viz
Sequence Manipulation Functions.
Indexy
K čemu slouží indexy jsem popisoval v souvislosti s podmínkou UNIQUE. Pokud vytvoříte v tabulce nějaký sloupec a až později se rozhodnete ke sloupci přidat podmínku UNIQUE, uděláte to prostě tak, že vytvoříte jeho „unikátní“ index.
Ke jménu indexu se dá říct téměř to samé, jako pro jméno sekvence.
Index neslouží jen k „hlídání“ unikátní hodnoty, ale taky k rychlejšímu vyhledávání v sloupci (sloupcích), nebo k rychlejšímu řazení podle zaindexovaného sloupce (sloupů).
Index můžete vytvořit příkazem CREATE INDEX.
Na úplný syntax příkazu CREATE INDEX se můžete podívat pomocí
metapříkazu \h CREATE INDEX.
Název indexu musí být v rámci databázového schématu unikátní.
Unikátní indexy
Příklad vytvoření (unikátního) indexu:
CREATE
rimmer1=> INSERT INTO cisla VALUES (1,1);
rimmer1=> INSERT INTO cisla VALUES (1,2);
rimmer1=> CREATE UNIQUE INDEX cisla_jedna_key ON cisla (jedna);
ERROR: Cannot create unique index. Table contains non-unique values
rimmer1=> CREATE UNIQUE INDEX cisla_dva_key ON cisla (dva);
CREATE INDEX
rimmer1=> INSERT INTO cisla(jedna) VALUES (1);
INSERT 0 1
rimmer1=> INSERT INTO cisla (dva) VALUES (2);
ERROR: duplicate key value violates unique constraint "cisla_dva_key"
DETAIL: Key (dva)=(2) already exists.
První pokus o vytvoření unikátního
klíče nezdařil, protože sloupec jedna neobsahoval
unikátní hodnoty. To jste asi pochopili z chybového hlášení.
Sloupec dva po vytvoření unikátního indexu
již nedovoluje vložit dvě stejné hodnoty.
Unikátní index umožňuje hlídat unikátnost řádků v několika sloupcích. Jinak řečeno, zabrání vložení řádku který by měl ve (všech) vybraných sloupcích stejné hodnoty jako jiný řádek. Vybranými sloupci myslím ty sloupce, které byli vybrány při vytváření indexu.
CREATE
rimmer1=> CREATE UNIQUE INDEX vektor_key ON vektor(i, j);
CREATE
rimmer1=> INSERT INTO vektor VALUES ('jedna', 3, 1);
rimmer1=> INSERT INTO vektor VALUES ('dva', 0, 5);
rimmer1=> INSERT INTO vektor VALUES ('dva', 1, 0);
rimmer1=> INSERT INTO vektor VALUES ('dva', 1, 0);
ERROR: duplicate key value violates unique constraint "vektor_key"
DETAIL: Key (i, j)=(1, 0) already exists.
Pokud byste chtěli, aby, kromě jiného, sloupec i nemohl obsahovat dvě stejné čísla (hodnoty v něm byly unikátní), mohli byste navíc vytvořit unikátní index jen pro tento sloupec.
Zrychlení selektů
Psal jsem, že indexy pomáhají urychlovat vyhledávání a třídění dat.
K tomu pomáhají jak unikátní indexy (bonus k unikátním indexům zdarma),
tak „obyčejné“ indexy (vytvořené bez klíčového slova UNIQUE).
Otázka zní, proč se nevytvoří pro každý sloupeček index automaticky?
Protože indexy něco stojí. Sice ne peníze, ale určitě místo na disku a pak hlavně čas aktualizace tabulky. Kdykoliv totiž vložíte do tabulky řádek, smažete ho nebo upravíte, musí se upravit každý index, kterého se změna týká. A to je poměrně náročná operace. Proto vytvářejte indexy jen tam, kde je budete potřebovat.
Použitím indexů se opravdu zrychlí SELECTy velmi výrazně. Proto na
vytváření indexů nezapomínejte! Vytvářejte indexy nad sloupečky, které
se objevují v klauzuli WHERE, ORDER BY a ON (pokud už nejsou vytvořené
implicitní díky primárním a cizím klíčům).
Pokud už vytvoříte unikátní index,
nemusíte vytvářet „obyčejný“ neunikátní index. Ten unikátní
vám poslouží pro zrychlení také. Další index by byla pro postgres jen práce navíc.
Řekněme například, že budu často SELECTovat řádky z tabulky vektor podle hodnoty sloupce jmeno. Pokud bych v tuto chvíli udělal takový SELECT, bude muset DBMS projít celou tabulku a zkontrolovat každý řádek, jestli je požadovaná hodnota v sloupci jmeno. Index si ale udržuje setříděné hodnoty sloupce (nad kterým je vytvořený). Najít něco v setříděných datech už je otázka chvilky, proto se díky indexu SELECT obvykle mnohonásobně zrychlí.
Výsledek SELECTu nijak nepřekvapil. Ani nijak nepoznáte, jestli se index skutečně použil, nebo ne. Poznat to můžete snad jen z toho, jak rychle se vám vrátí výsledek. A to ještě jen u tabulek, které obsahují hodně dat. U tabulky, kde moc dat naní, se může Postgres rozhodnout index nepoužít, protože koukání „stranou“ by v takovém případě byla jen práce navíc. Stejně tak, pokud selektujete většinu dat z tabulky, může si Postgres usmyslet nepoužít indexy, protože přečtení celé tabulky bez koukání na indexy bude rychlejší. Chytrej je ten Postgres, moc chytrej. (Jiné databáze samozřejmě taky :-)
V tabulce vektor existuje už unikátní index nad sloupečky i a j. Postgres umí tento index použít i při prohledávání jednoho sloupce, takže by bylo zbytečné vytvářet index nad sloupcem i nebo j.
Stejně jako urychlují indexy SELECTy, tak mohou urychlovat i
příkazy UPDATE a DELETE,
pokud se v nich objeví klauzule WHERE,
která může index využít.
Indexy nad výrazy (expression)
Index můžete vytvářet nejen nad sloupcem (nebo sloupci), ale i nad výrazy. Do indexu se pak ukládají seřazené hodnoty výsledků výrazu. Aby to mělo cenu, musí být výsledek výrazu neměnný (immutable). To znamená, že pro stejné zadané hodnoty do výrazu musí výraz vrátit vždy stejné výsledky. Ve výrazu nemůžete pracovat s náhodnými čísly, s časem, s hodnotami z extra tabulky atp.
Výraz by měl být uzavřený v závorkách. Proto jsou v následujícím příkladu závorky 2x.
Od této chvíle, když použijete v SELECTu výraz i+j (tentokrát
už nemusí být v závorkách), použije Postgres index vektor_sum.
Ovšem pozor. Výraz musí být stejný jako při vytváření indexu. Jakákoliv malinká odchylka může způsobit (a způsobí), že se index nepoužije.
Smazání indexů
K mazání indexů slouží příkaz DROP INDEX.
V Postgresu musí být jméno indexu unikátní pro celou databázi, proto stačí zadat jen jeho jméno.
V Postgresu jde použít s DROP INDEX i iF EXISTS,
což zajistí, že pokud náhodou index zadaného jména neexistuje, nevyhodí
se žádná chyba, která by mohla třeba zastavit provádění skriptu.
EXPLAIN
O tom, jestli se použijí indexy nebo ne, rozhoduje „plánovač“. Ten naplánuje jak se SELECT skutečně provede na základě SQL dotazu, struktury tabulky a indexů a obsahu tabulky.
Příkaz EXPLAIN vám ukáže, jak si to plánovač naplánoval.
V následujících příkladech předpokládám, že je vytvořená tabulka vektor, unikátní index nad sloupečky i a j vektor_key, index vektor_jmeno_ix nad sloupečkem jmeno. Naopak (zatím) neexistuje index vektor_sum nad výrazem (i+j).
Podívejte se, jak vypadá výstup z EXPLAIN pro SELECT všech hodnot z tabulky vektor.
První co se dočtete je, že se provede sekvenčí čtení tabulky vektor. Sekvenční čtení znamená, že se bude číst každý řádek tabulky, jeden za druhým. Indexy se vůbec nepoužijí. Taky proč, chcete přece vypsat všechny data z tabulky, ani je nijak neřadíte, tak k čemu indexy?
V závorce pak vidíte cost. To určuje jak dlouho (zhruba – je to jen odhad) bude příkaz trvat. První číslo říká, jak dlouho to bude trvat, než bude možné něco začít vracet na výstup a druhé číslo celkový čas příkazu.
Protože SELECT v příkladu nemusí nic JOINovat ani
třídit, může rovnou začít posílat výstup. Proto je první číslo 0.
Druhé číslo udává, celkový čas. Jednotkou tohoto čísla ale není
vteřina, ani nic podobného.
Celková doba běhu příkazu bude nějakým násobkem tohoto čísla,
ale těžko říct jakým. To záleží na nastavení Postgresu, na
prostředí ve kterém běží (operační systém, souborvý systém atp.),
na hardware atd. Číslo můžete použít k porovnávání různých selektů,
který bude rychlejší, jinak vám moc neřekne.
Následuje rows, který odhaduje počet řádků, který se vrátí. Poslední je width, který odhaduje, kolik bajtů bude mít průměrný vrácený řádek.
Teď zkusím EXPLAIN na SELECTu, který by měl
využít index vektor_jmeno_ix.
QUERY PLAN
--------------------------------------------------------
Seq Scan on vektor (cost=0.00..1.04 rows=1 width=52)
Filter: (jmeno = 'dva'::bpchar)
(2 řádky)
rimmer1=> SELECT * FROM vektor WHERE jmeno = 'dva';
jmeno | i | j
------------+---+---
dva | 0 | 5
dva | 1 | 0
(2 řádky)
A ejhle, on se index zase nepoužívá. To proto, že plánovač
plánuje i na základě obsahu tabulky. A protože tabulka
obsahuje málo řádek, nevyplatilo by se koukat bokem na index.
Takže sekvenční čtení je pořád nejlepší volba. Všiměte si,
že plánovač špatně odhadl počet řádek, který příkaz SELECT
vrátí. Odhaduje, že se vrátí 1, ale ve skutečnosti se vrátí dva.
Možná, že když si to budete zkoušet u sebe, tak se strefí.
Je to jen odhad.
Abyste si mohli EXPLAIN vyzkoušet, připravil jsem pro vás
dávkový soubor s 111000 INSERTy do tabulky vektor
vektor.sql.zip.
Je to velký soubor, takže jsem jej zazipoval a obsahuje jen
příkaz pro smazání všech řádků tabulky vektor a pak
INSERTy. Neobashuje CREATE TABLE ani vytváření INDEXů.
Chtěl jsem, aby byl skript kompatibilní se všemi DBMS, které tu probírám.
Nechci tak velký soubor nabízet v několika verzích, aby ste mi
nezahltili server :-).
Před použitím tohoto dávkového souboru doporučuji smazat a znovu vytvořit
tabulku vektor – tím se smažou i indexy. Indexy
znovu vytvořte až po nahrání dat. Je výrazně rychlejší vytvořit
index až nad naplněnou tabulkou, než při každém INSERTu index aktualizovat.
Při 111000 řádcích už to pocítíte.
Během nahrávání skriptu se můžete připojit k databázi a zkusit si
příkaz SELECT count(*) from vektor; Uvidíte, jak daleko s nahráváním jste.
A teď zkusím EXPLAIN znovu.
QUERY PLAN
-------------------------------------------------------------------------------
Index Scan using vektor_jmeno_ix on vektor (cost=0.00..8.34 rows=4 width=19)
Index Cond: (jmeno = 'dva'::bpchar)
(2 řádky)
rimmer1=> SELECT * FROM vektor WHERE jmeno = 'dva';
jmeno | i | j
------------+---+---
dva | 0 | 5
dva | 1 | 0
(2 řádky)
No vida, tentokrát už se použije index vektor_jmeno_ix. Odhad výsledného počtu řádků je zase špatně, ale na to, že je v tabulce 111000 řádků je docela blízko :-).
Teď zkusím další EXPLAIN. Připomínám, že neexistuje index
vektor_sum.
QUERY PLAN
------------------------------------------------------------
Seq Scan on vektor (cost=0.00..2929.00 rows=555 width=19)
Filter: (((i + j) >= 50000) AND ((i + j) <= 500000))
(2 řádky)
rimmer1=> SELECT * FROM vektor WHERE i + j BETWEEN 50000 and 500000;
jmeno | i | j
------------+--------+--------
test | 349191 | 57865
test | 20151 | 222418
test | 2246 | 323118
test | 122626 | 156366
test | 401753 | 2168
test | 155143 | 258160
test | 95297 | 303726
test | 93011 | 200915
test | 9690 | 119219
(9 řádek)
Odhad celkové doby je 2929 (něčeho). To je docela dost :-). Odhadovaný počet vrácených řádek je 555. A skutečnost? Pouze 9.
Teď vytvořím index pro výraz (i+j) a zkusím EXPLAIN ještě
jednou:
rimmer1=> explain SELECT * FROM vektor WHERE i + j BETWEEN 50000 and 500000;
QUERY PLAN
----------------------------------------------------------------------------
Bitmap Heap Scan on vektor (cost=13.96..723.10 rows=555 width=19)
Recheck Cond: (((i + j) >= 50000) AND ((i + j) <= 500000))
-> Bitmap Index Scan on vektor_sum (cost=0.00..13.82 rows=555 width=0)
Index Cond: (((i + j) >= 50000) AND ((i + j) <= 500000))
(4 řádky)
Tentokrát se plán rozdělil do dvou kroků. Poslením krokem je Bitmap Heap Scan. Jeho součástí je Bitmap Index Scan. Všiměte si, že Bitmap Heap Scan začíná až po index scanu, takže jeho první cost je o malilinko větší než druhá cost index scanu.
Index Scan se použije na vyfiltrování řádků a odhaduje se, že jich vrátí 555. Bitmap Heap Scan pak už jen řádky vypíše, žádný neodfiltruje, takže odhad počtu řádků je pořád 555. Index scan neposílá svůj výsledek na výstup. Až skončí, předá svůj výsledek Bitmap Heap Scanu.
QUERY PLAN
----------------------------------------------------------------------------------
Sort (cost=748.39..749.78 rows=555 width=19)
Sort Key: i
-> Bitmap Heap Scan on vektor (cost=13.96..723.10 rows=555 width=19)
Recheck Cond: (((i + j) >= 50000) AND ((i + j) <= 500000))
-> Bitmap Index Scan on vektor_sum (cost=0.00..13.82 rows=555 width=0)
Index Cond: (((i + j) >= 50000) AND ((i + j) <= 500000))
(6 řádek)
Výsledek tohoto příkladu je stejný jako toho předchozího, jen se jako poslední
provede sortování podle sloupce i. (Sortování se provede na
výsledku Bitmap Heap Scan, který se provede na výsledku Bitmap Index Scan.)
A tohle už je poslední příklad. Vidíte, že se vrátí všechny řádky tabulky, že to bude trvat dlouho a že se použije pro třídění index vektor_key, který se bude číst pozpátku (protože je ORDER v sestupném pořadí).
Pokud vás EXPLAIN nadchnul, podívejte se do dokumentace na
Using
EXPLAIN, kde se dozvíte více podrobností, třeba něco o EXPLAIN ANALYZE.
MySQL
MySQL nemá sekvence. Můžete používat AUTO_INCREMENT,
ale tomu nemůžete nastavit vlastnosti jako INCREMENT BY, CYCLE
či MAXVALUE. Největším omezením je nemožnost použití sekvence na více jak
jednu tabulku. Existuje způsob, jak si vytvořit vlastní funkci nextval,
ale to je zatím nad rámec toho, co jsem vás tu naučil.
MySQL neumí vytvořit index nad výrazem. Jediný zatím dostupný způsob jak to obejít je vytvořit extra sloupeček, kam si uložíte výsledky výrazu a ten zaindexuje. Sice tím porušíte 3NF, ale co už.
V MySQL jsou indexy součástí tabulky, takže můžete mít více indexů stejného jména, pokud se vztahují na jiné tabulky. Důsledkem toho je, že když index mažete, musíte říct nejen jeho jméno, ale i jméno tabulky.
EXPLAIN
Výstup tohoto příkladu se v MySQL od Postgresu dost liší.
+----+-------------+--------+------+-----------------+-----------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+-----------------+-----------------+---------+-------+------+-------------+
| 1 | SIMPLE | vektor | ref | vektor_jmeno_ix | vektor_jmeno_ix | 31 | const | 2 | Using where |
+----+-------------+--------+------+-----------------+-----------------+---------+-------+------+-------------+
Z výstupu můžete vyčíst, že se MySQL může použít vektor_jmeno_ix a také se
rozhodl použít index vektor_jmeno_ix. Očekávaný
počet prohledávaných řádků jsou 2. (Tabulka je před nahráním skriptu vektor.sql.)
+----+-------------+--------+------+---------------+------+---------+------+------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+------+----------------+
| 1 | SIMPLE | vektor | ALL | NULL | NULL | NULL | NULL | 3 | Using filesort |
+----+-------------+--------+------+---------------+------+---------+------+------+----------------+
mysql> explain SELECT i,j FROM vektor ORDER BY i DESC;
+----+-------------+--------+-------+---------------+------------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+------------+---------+------+-------+-------------+
| 1 | SIMPLE | vektor | index | NULL | vektor_key | 10 | NULL | 3 | Using index |
+----+-------------+--------+-------+---------------+------------+---------+------+-------+-------------+
V dalším příkladu vydíte, že se MySQL se chová oproti Postgresu zase trochu rozdílně. Rozhodl se využít index vektor_key pouze v druhém případě, kdy se tahají z tabulky jen sloupce, které jsou v indexu (v takovém případě se ani nemusí dívat do tabulky, všechna data vysosá z indexu). (Viz ORDER BY Optimization.)
Pro podrobnější vysvětlění výstupu z EXPLAIN se podívejte
na EXPLAIN Output Format.
SQLite
SQLite nemá sekvence. Používá jen AUTOINCREMENT. Nevýhody jsou stejné jako u MySQL.
SQLite neumí vytvořit index nad výrazem. Řešit se to dá stejně jako v MySQL.
Indexy v SQLite musí být unikátní v rámci celého schématu, takže jako v Postgresu.
V SQLite se používá pro zobrazení exekučního plánu příkaz EXPLAIN QUERY PLAN
(existuje i verze bez QUERY PLAN, ale ta zobrazí trochu něco jiného).
Více viz The EXPLAIN QUERY PLAN Command.
Oracle
Oracle sekvence má, ale nemůže je použít jako defaultní hodnoty. O tom jsem už psal v kapitole o vytváření relací. Existuje ještě další podivnost, oproti Postgresu:
oracle> INSERT INTO mutant VALUES('jedna', mutant_c_seq.NEXTVAL, mutant_c_seq.NEXTVAL);
oracle> INSERT INTO mutant VALUES('dva', mutant_c_seq.NEXTVAL, mutant_c_seq.NEXTVAL);
oracle> INSERT INTO mutant VALUES('tri', mutant_c_seq.NEXTVAL, mutant_c_seq.NEXTVAL);
oracle> SELECT * FROM mutant;
SLOVO C1 C2
jedna 1 1
dva 2 2
tri 21 21
První čeho si všimnete je,
že NEXTVAL vrací pořád stejné číslo v rámci jednoho SQL dotazu. To se může
někdy hodit a někdy ne. Těžko říct, jestli je lepší chování Postgresu nebo Oracle.
Rozhodněte si to sami :-).
Druhá zajímavá věc je, že na třetím řádku sekvence poskočila o cca 20 záznamů.
To je způsobené tím, že sekvence v Oracle pužívají defaultně tzv. CACHE
pro 20 čísel. Funguje to tak, že se ze sekvence uzme 20 čísel, která se pak jedno
za druhým používají. Pak se vezme dalších 20 čísel atd.
Příkazy pro insert jsem spouštěl v Apexu, tj. přes webové rozhraní a mezi druhým
a třetím příkzem došlo k expiraci sezení, takže se cache smazala a pro třetí příkaz
se vytvořilo nové spojení s novým cachováním sekvence. Číslo tak poskočilo až za dvacítku.
Co z toho plyne? Sekvence, kvůli cachování, nejsou bez „děr“. Výhodou je, že se čísla generují několikanásobně rychleji. Pokud INSERTujete hodně řádků, kde sekvenci používáte, je to znát.
Pokud nechcete mít sekvence s dírama, uveďte při jejich vytváření NOCACHE.
Pokud chcete nastavit vlastní velikost CACHE (čím větší, tím rychlejší, ale taky možnost
vzniku větších děr), uveďte CACHE n, kde n je
číslo větší než 1.
V Postgresu taky můžete použít CACHE. Jen místo NOCACHE
se používá CACHE 1, což je taky v Postgresu defaultní nastavení.
oracle> SELECT test_cycle_seq.NEXTVAL, test_cycle_seq.NEXTVAL,
test_cycle_seq.NEXTVAL, test_cycle_seq.NEXTVAL from dual;
NEXTVAL NEXTVAL NEXTVAL NEXTVAL
6 6 6 6
oracle> SELECT test_cycle_seq.NEXTVAL, test_cycle_seq.NEXTVAL,
test_cycle_seq.NEXTVAL, test_cycle_seq.NEXTVAL from dual;
NEXTVAL NEXTVAL NEXTVAL NEXTVAL
7 7 7 7
-- dál už je to asi jasné
Oracle umí vytvořit indexy nad výrazy a index má platnost v rámci databáze,
v tom se chová stejně jako Postgres. Jen neumí použít při mazání indexu IF EXISTS.
Místo toho to jde nasimulovat takto: (podobně jako při mazání tabulky).
Plánovač dotazu je v Oracle o ždibec chytřejší, takže dokáže použít index vektor_sum
jak s výrazem (i+j), tak (j+i), ale s (i+j+1) si už
taky neporadí. K tomu, abyste poznali kdy se index bude používat a kdy ne slouží už dobře
známý příkaz EXPLAIN.
EXPLAIN PLAN FOR
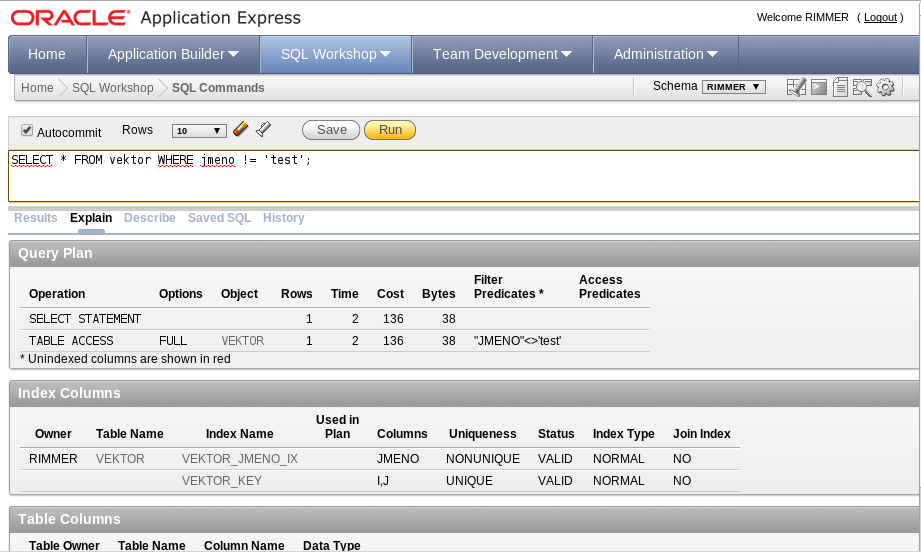
Explain v Apexu
Exekuční plán (Query Plan) se může zobrazit v Apexu pomocí záložky explain (viz obrázek). Ve výsledku uvidíte 3 tabulky. První popisuje samotný exekuční plán, ve druhém uvidíte indexy které jsou k dispozici a indexy, které se použijí (v příkadu na obrázku se nepoužijí žádné).
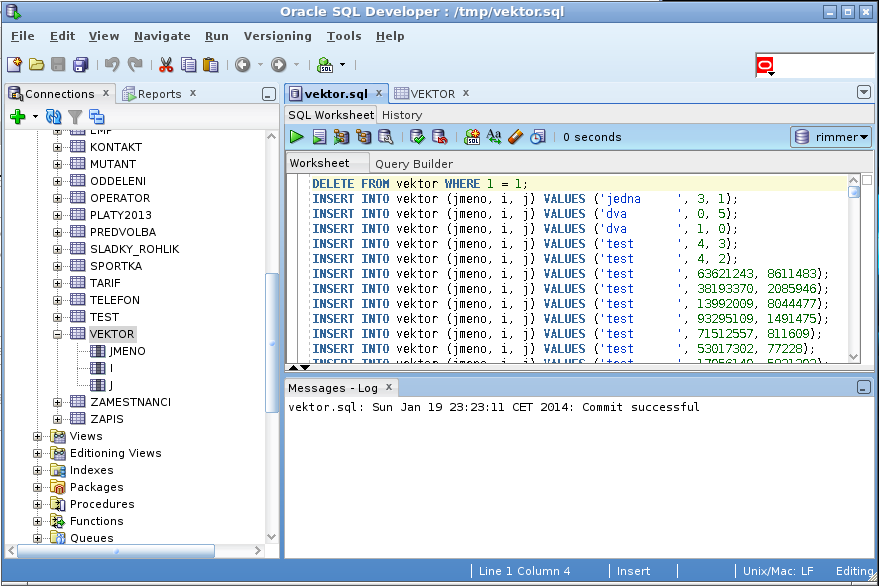
Import vektor.sql
Pokud budete chtít nahrát skript vektor.sql (viz výše),tak přes Apex to bohužel nepůjde
kvůli jeho velikosti. Kupodivu jej ale můžete bez větších problémů otevřít
a spustit v Oracle SQL developeru.
Po spuštění skriptu (to druhé tlačítko se zeleným trojúhelníkem a listem papíru)
nezapomeňte kliknout na tlačítko pro
potvrzení transakce (tlačítko se zelenou fajfkou),
jinak se provedené změny do databáze neuloží.
Pokud chcete použít SQL příkaz, pak se jmenuje
EXPLAIN PLAN FOR. Tento příkaz ovšem exekuční plán
nevypíše, ale uloží jej do systémové tabulky PLAN_TABLE,
ze které ho dostanete příkazem SELECT * FROM TABLE(dbms_xplan.display);
(Proč to musí být v Oracle vždycky tak složitý?)
Explained.
oracle> SELECT * FROM TABLE(dbms_xplan.display);
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
Plan hash value: 3437271467
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 26 | 2 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| VEKTOR_KEY | 1 | 26 | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
1 - access("I"=4)
Note
-----
- dynamic sampling used for this statement (level=2)
17 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 2137789089
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 8168 | 16336 | 29 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Další informace můžete najit na wiki, nebo v dokumentaci.
