

Sloupcová omezení, Indexy
Pokud vytváříte tabulku (příkazem CREATE TABLE), můžete mít na data, která se budou ukládat do sloupců, speciální požadavky. Nejdůležitější z nich proberu v této kapitole a v kapitole o relacích.
V této kapitole se bude vytvářet hodně tabulek, které už později nebudou potřeba, tak si je na konci můžete smazat příkazem DROP TABLE.
Integritní omezení
Integritní omezení (Integrity constraints) je správnější název než soupcová omezení. Existují totiž omezení, která se netýkají jen hodnot (jednoho) sloupce, ale i vazeb mezi sloupci. (Viz relace v další kapitole).
Integritní omezení říkají, jak mají vypadat data ukládaná do tabulky (sloupce).
Mezi integritní omezení patří (neformálně) už datový typ sloupce. Když si vytvoříte datový sloupec typu INTEGER, už do něj nemůžete vložit text. (O to se stará DBMS.)
Formálně je integritním omezením i defaultní hodnota (ikdyž to ve skutečnosti není žádné omezení). Defaultní (implicitní) hodnota říká, co se má uložit za hodnotu do sloupečku, když při INSERTU hodnotu sloupečku neurčíte explicitně.
Další constrainty jsou: NOT NULL, UNIQUE, CHECK, a pro relaci PRIMARY KEY (primární klíč) a FOREIGN KEY (cizí klíč).
Defaultní hodnoty
Defaultní hodnota sloupce je taková hodnota, která se do sloupce
dosadí automaticky, pokud neurčíte jeho hodnotu. Pokud defaultní
hodnotou neurčíte, ani neurčíte hodnotu sloupce v příkazu INSERT,
je automaticky dosazena hodnota NULL
(NULL je defaultní hodnota pro defaultní hodnotu :-).
Defaultní hodnoty vám mohou ušetřit trochu toho psaní a navíc vám zajistí,
že ve sloupci nebudete mít tu ošklivou hodnotu NULL.
(Typicky datový typ BOOL
většinou není dobré nechávat nevyplněný).
Příklad: Dejme tomu, že pravidelně sázím sportku za 60 Kč. Vytvořím si tabulku, kde si budu ukládat, kolik jsem vsadil, kdy a kolik jsem vyhrál. Záznam o sázce vložím vždy ten den, kdy vsadím. Záznam o výhře budu měnit dodatečně až po tahu sportky.
Vytvořím tedy defaultní hodnotu pro sázku (60 Kč), ale i pro výhru (0 Kč). Když pak nevyhraji, nemusím se obtěžovat záznam měnit a nebudu mít nikde ve sloupci výher hodnotu NULL (pokud si jí tam schválně nevložím :-)). Protože sázky i výhry budou v celých korunách, použiji jako typ celé číslo (integer).
Klíčové slovo DEFAULT s hodnotou se píší vždy až za datový typ sloupečku.
Doposud jsem při INSERTu vkládal vždy hodnoty pro všechny sloupečky tabulky. Aby měla hodnota DEFAULT nějaký smysl, musí existovat způsob, jak vložit hodnoty jen pro některé sloupečky. A ten teď ukážu v příkladu: za jménem tabulky se do závorek vypíší jména sloupců, do kterých chci vložit nějakou hodnotu explicitně (do ostatních se vloží DEFAULT hodnota).
Nyní vložím do tabulky sportka několik „sázek“:
Nechme stranou, že jsem tak trochu gambler. Výsledek je:
Defaultní hodnotou může být také výraz. Opět ukážu na příkladě:
Představte si, že vedete malý obchod s cukrovím. Jedno ze zboží, které objednáváte, je „Sladký rohlík“. Většinou jich objednáváte 100 Kusů a jejich trvanlivost je 5 dní. Ale pokud si je objednáte ve speciálním balení, bude jejich trvanlivost delší. Musíte také vědět, kdo vám rohlíky dovezl (kvůli případné reklamaci). Váš obvyklý závozník se jmenuje Tomáš Tlustý (ale někdy se může stát, že potřebujete větší množství a tak si objednáte i u někoho jiného). Přehled o zboží si pak budete udržovat v takovéto tabulce:
Poznámka: current_date je funkce, která vrací hodnotu aktuálního datumu. Funkcemi se budu zabývat později.
Bohužel nemůžete ve výrazu použít hodnotu sloupce (nejde
použít jako defaultní hodnotu ve sloupci spotrebovat_do
dovezeno + 5). Další malou „nepříjemností“ je to, že příkaz INSERT
musí obdržet jako argument hodnotu alespoň jednoho sloupce (i když
mají všechny sloupce svou defaultní hodnotu). Vyzkoušejte.
Dobrá zpráva je, že můžete pro hodnotu sloupce použít klíčové slovo DEFAULT.
Je to určitě lepší, než psát explicitně defaultní hodnotu, zvlášť když tento SQL dotaz používáte častěji
(máte ho třeba někde uložený) a defaultní hodnota se v tabulce může změnit.
zavoznik | pocet | dovezeno | spotrebovat_do
--------------+-------+------------+----------------
Tomáš Tlustý | 100 | 2013-11-28 | 2013-12-03
Tomáš Tlustý | 100 | 2013-11-28 | 2013-12-03
(2 řádky)
Podmínka CHECK
Za klíčovým slovem CHECK následuje podmínka, podobně jako u
WHERE (Jen si odmyslete podmínky s
NULL, IN a ALL). Podmínka se uvádí za klíčovým slovem CHECK v
závorce. Podmínka (constraint) určí, jaké hodnoty budete moci do tabulky
vložit (pouze takové, co podmínce vyhoví).
Příklad: budete udržovat databázi zboží na skladě. Na zboží máte následující požadavky:
- Nemůžete mít na skladě záporné množství zboží, tak si v databázi určíte podmínku, že množství zboží nesmí být menší než 0.
- Máte také omezené místo ve skladu, proto nesmí žádné zboží přesáhnout počet 500 kusů (tolik zboží byste ani nestihli do příští objednávky prodat). Když se pak pokusíte odečíst z databáze více zboží, než máte na skladě, nebo naopak více zboží objednat, než kolik můžete přijmout, nepůjde to.
- Zboží musí mít také svou cenu.
- Cena by měla být vyšší než 0.
Tabulka s takovými omezeními může vypadat následovně:
Teď se pokusím vložit nějaké hodnoty do tabulky:
INSERT 0 1
rimmer1=> INSERT INTO zbozi VALUES ('Tarasnice', 0, 500);
INSERT 0 1
rimmer1=> UPDATE zbozi SET pocet = pocet + 100;
ERROR: new row for relation "zbozi" violates check constraint "zbozi_pocet_check"
DETAIL: Failing row contains (Kulomety, 600, 1499.90).
rimmer1=> INSERT INTO zbozi VALUES ('Samopaly', 501, 1499.90);
ERROR: new row for relation "zbozi" violates check constraint "zbozi_pocet_check"
DETAIL: Failing row contains (Samopaly, 501, 1499.90).
rimmer1=> INSERT INTO zbozi(nazev, pocet) VALUES ('Samopaly', 300);
INSERT 0 1
rimmer1=> INSERT INTO zbozi(nazev, pocet, cena) VALUES ('Samopaly', 300, -1000);
ERROR: new row for relation "zbozi" violates check constraint "zbozi_cena_check"
DETAIL: Failing row contains (Samopaly, 300, -1000.00).
Všimněte si, jaké si vymyslel Postgres pro „check constraint“ názvy.
Záznamy o Kulometech a Tarasnicích jsem vložil bez problémů.
Splňovali všechny podmínky.
Pokus o zvýšení všech položek o 100 kusů neprošel, neboť jedna položka
(Kulomety) by nesplnila sloupcové omezení pocet <= 500;.
Příkaz UPDATE se neprovedl
a nebyla změněná žádná řádka v databázi.
Zajímavý je předposlední příkaz INSERT. Po jeho provedení
existuje položka, jejíž cena nebyla udána a je tedy NULL.
Ale v požadavcích na tabulku bylo, aby byla u každého zboží cena! Tento
problém vyřeší podmínka NOT NULL.
Podmínka NOT NULL
Toto sloupcové omezení zabrání vytvoření sloupce v řádku s hodnotou
NULL.
Problém s cenou z předchozího příkladu se vyřeší kombinací
podmínek CHECK a NOT NULL.
Název zboží i počet by také neměli být nikdy prázdné,
takže i k nim přidám podmínku NOT NULL.
Tabulku vytvořím znova, proto ji nejdřív smažu:
Integritní omezení se píší za datovým typem, ale je jedno v jakém pořadí.
Podmínka UNIQUE
Podmínka UNIQUE zajišťuje, že v sloupci budete mít jen
jedinečné hodnoty (pro všechny řádky tabulky). V sloupci tedy nebudou
dvě hodnoty stejné, ale může tam být několik
položek s hodnotou NULL (nepoužijete-li sloupcové omezení NOT
NULL).
NULL totiž znamená „nevím co je tam za hodnotu“, NULL se ničemu nerovná, proto se bere jako unikátní hodnota.
Ukáži na příkladu, jak se dají sloupcové podmínky kombinovat. Řekněme, že chci mít tabulku, kam smí být proveden jen jeden zápis denně:
current_date je funkce, která vrací hodnotu aktuálního datumu.
Funkcemi se budu zabývat později.
Index a DROP INDEX
Určitě jste si v předchozím příkladě všimli, že se kromě tabulky ještě vytvořil index zapis_datum_zapisu_key. Jak si Postgres vytvořil jeho jméno je asi jasné.
Co je index
Index je nepovinná datová struktura (databázový objekt) asociovaná s tabulkou. Hlavní cíle indexu jsou:
- Zajistit integritu dat
- unikátnost (unique, primary key)
- odkazy (references – cizí klíče)
- Umožnit rychlejší přístup k datům
- optimalizace rychlosti provádění dotazů
- snazší řazení dat dle obsahu sloupce
Zatím jediným databázovým objektem se kterým jste přímo pracovali byla tabulka. Tabulka je v databázích to nejdůležitější, kolem čeho se všechno točí. Ale existují i další databázové objekty, jako je například zmíněný index.
Index funguje podobně jako rejstřík na konci knihy. Umožní DBMS rychle najít v datech to, co potřebuje.
Index pro podmínku UNIQUE slouží k tomu, aby mohl Postgres kontrolovat, že jsou data v sloupci datum_zapisu jedinečná. Pomocí indexu DBMS rychle zjistí, zda nová vkládaná hodnota někde ve sloupci už je nebo ne. O to, jak přesně to DBMS s indexem dělá se nemusíte moc starat. Důležité je jen vědět, že index na jednu stranu urychluje práci při hledání dat, na druhou stranu zabírá místo na disku a zpomaluje INSERT a UPDATE (protože se musí aktualizovat nejen tabulka, ale i index). Z tohoto důvodu se nevytváří index u každého sloupečku, ale jenom tam, kde se dá očekávat, že bude potřeba.
Další využití indexů (krom UNIQUE) bude popsáno v dalších kapitolách.
Zrušení indexu
Příkaz pro zrušení indexu je jednoduchý:
Ze syntaxe DROP INDEX se dá uhádnout, že název indexu musí být unikátní
pro celou databází (resp. schéma).
Indexy, které máte v databázi, zjistíte
metapříkazem \di.
Tabulka "public.zapis"
Sloupec | Typ | Modifikátory
----------------+-----------------------+-----------------------------------------
jmeno_zadatele | character varying(20) | not null
text_zapisu | text |
datum_zapisu | date | not null implicitně ('now'::text)::date
Indexy:
"zapis_datum_zapisu_key" UNIQUE CONSTRAINT, btree (datum_zapisu)
Kontrolní pravidla:
"zapis_datum_zapisu_check" CHECK (datum_zapisu >= 'now'::text::date)
rimmer1=> \di
Seznam relací
Schéma | Jméno | Typ | Vlastník | Tabulka
--------+------------------------+-------+----------+---------
public | zapis_datum_zapisu_key | index | petr | zapis
(1 řádka)
Pokud zrušíte index, podmínka UNIQUE bude z tabulky odstraněna.
Index nelze smazat, pokud existuje podmínka (constraint), která jej využívá.
Jak se dá odstranit podmínka (drop constraint) proberu v
kapitole o ALTER TABLE.
Smazáním tabulky se smažou i její indexy.
Další informace lze najít v odstavci o vytváření indexu.
MySQL/MariaDB
Typy tabulek
V kapitole o CREATE TABLE jsem
vám zatajil o MySQL jednu důležitou věc. V MySQL existuje několik
databázových „strojů“ (engine), které se starají o fyziké
vykonávání SQL příkazů. Mezi nejpoužívanější patří MyISAM
a InnoDB.
Engine MyISAM byl dříve defaultní. Je velmi rychlý rychle ukládá i načítá data, ale nevynucuje integritní omezení. Když vytvoříte tabulku s Engine = MyISAM, můžete sice uvádět integritní omezení, ale MyISAM je potichu ignoruje.
Engine InnoDB je pomalejší, protože naopak integritní omezení respektuje. Dnes je to v databázi defaultní engine (tj. když při vytváení tabulky neuvedete engine, použije se InnoDB). Defaultní engine se ale dá v databázi nastavit, takže se nemůžete na 100% spolehnout na to, který je defaultní. Proto je rozumné vždycky uvádět, že chcete InnoDB.
Změny
V MySQL není funkce TO_DATE, takže INSERTy vypadají
jednoduše takto:
MySQL umí jako defaultní hodnotu aktuálního času použít jen s
datovým typem TIMESTAMP, který ukládá datum i čas.
Navíc je omezen jen na jednu takovou defaultní hodnotu na tabulku.
Tabulku sladky_rohlik můžete vytvořit takto:
Do tabulky se pak musí hodnota do sloupce spotrebovat_do explicitně vložit, jinak v něm bude 0 ('0000-00-00').
VALUES(DEFAULT, DATE_ADD(NOW(), INTERVAL +5 DAY));
Query OK, 1 row affected, 1 warning (0.08 sec)
mysql> SHOW WARNINGS;
+-------+------+-----------------------------------------------------+
| Level | Code | Message |
+-------+------+-----------------------------------------------------+
| Note | 1265 | Data truncated for column 'spotrebovat_do' at row 1 |
+-------+------+-----------------------------------------------------+
1 row in set (0.00 sec)
NOW() vrací datum i čas. Při ukládání do tabulky se do
sloupce spotrebovat_do typu DATE ukládá jen datum,
takže čas je „oříznut“.
Varováním se tak netřeba znepokojovat, je to úplně normální.
MySQL vám sice umožní zapsat podmínku CHECK, ale za 1.
jí musíte uvést pří definici sloupce až jako poslední (to pro Postgres neplatí) a za 2. jí úplně ignoruje.
INSERT nezpůsobí žádnou chybu.
Jak už jsem psal, CHECK se musí psát v MySQL až za ostatní
integritní omezení (a MySQL ho ignoruje). (MySQL umožňuje
zapsat CHECK čistě kvůli větší přenositelnosti SQL příkazů
mezi různými databázemi.)
mysql> CREATE TABLE zbozi (
nazev VARCHAR(20) NOT NULL,
pocet INTEGER NOT NULL CHECK (pocet >= 0 AND pocet <= 500),
cena NUMERIC(8,2) NOT NULL CHECK (cena > 0)
);
mysql> INSERT INTO zbozi(nazev, pocet) VALUES ('Samopaly', 300);
Query OK, 1 row affected, 1 warning (0.03 sec)
mysql> SHOW WARNINGS;
+---------+------+-------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------+
| Warning | 1364 | Field 'cena' doesnt have a default value |
+---------+------+-------------------------------------------+
1 row in set (0.00 sec)
mysql> select * from zbozi;
+----------+-------+------+
| nazev | pocet | cena |
+----------+-------+------+
| Samopaly | 300 | 0.00 |
+----------+-------+------+
1 row in set (0.01 sec)
MySQL si stěžuje, že sloupeček cena nemá definovanou hodnotu.
NULL má zakázáno, tak si domyslel 0.00.
Další změna definice tabulky je kvůli omezení TIMESTAMP
(jen jeden sloupeček TIMESTAMP může mít v tabulce jako defaultní
hodnotu aktuální čas). A CHECK se musí napsat až na konci integritních
omezení …
jmeno_zadatele VARCHAR(20) NOT NULL,
text_zapisu TEXT,
datum_zapisu TIMESTAMP UNIQUE NOT NULL
DEFAULT current_timestamp
CHECK (datum_zapisu >= current_date)
);
SHOW CREATE TABLE zapis;
CREATE TABLE `zapis` (
`jmeno_zadatele` varchar(20) COLLATE utf8mb4_czech_ci NOT NULL,
`text_zapisu` text COLLATE utf8mb4_czech_ci,
`datum_zapisu` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
UNIQUE KEY `datum_zapisu` (`datum_zapisu`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_czech_ci;
SHOW CREATE TABLE ukazuje dvě zajímavé věci. Za 1. zmizela
podmínka CHECK (já vám to říkal že jí MySQL ignoruje) a
za 2. podmínka UNIQUE se transformovala do indexu
(UNIQUE KEY)
jménem datum_zapisu (nad sloupečkem datum_zapisu,
který je napsaný na konci v závorkách). Shodnost názvu indexu a jména
sloupečku je čistě „náhodná“ (existuje způsob, jak si
jméno indexu definovat, ale o tom až jindy).
V MySQL mají indexy platnost v rámci tabulky. Takže můžete mít indexy stejného jména, pokud se týkají různých tabulek. Z toho taky plyne, že když pracujete s indexy, musíte říct nejen jaký index (jeho jméno) ale i z jaké tabulky.
-- výsledkem je jedna dlouhá řádka, takže jí sem celou nevypíšu.
-- zajímavý je jen sloupeček Key_name, kde najdete jméno indexu (datum_zapisu)
+-------+------------+--------------+--------------+--------------+-- ...
| Table | Non_unique | Key_name | Seq_in_index | Column_name | C ...
+-------+------------+--------------+--------------+--------------+-- ...
| zapis | 0 | datum_zapisu | 1 | datum_zapisu | A ...
+-------+------------+--------------+--------------+--------------+-- ...
Smazáním UNIQUE indexu zrušíte integritní omezení UNIQUE.
SHOW CREATE TABLE zapis;
CREATE TABLE `zapis` (
`jmeno_zadatele` varchar(20) COLLATE utf8mb4_czech_ci NOT NULL,
`text_zapisu` text COLLATE utf8mb4_czech_ci,
`datum_zapisu` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_czech_ci
Všimněte si, že DROP INDEX zmiňuje nejen jaký index, ale i z jaké tabulky smazat.
SQLite
SQLite je na tom kupodivu o mnoho lépe než MySQL.
Sice také nemá funkci TO_DATE, ale nedělá mu problém
vytvořit dva sloupce s defaultní hodnotou “aktuální čas“
a dokonce rozumí podmínce CHECK! (Styď se MySQL, styď se!)
Podmínka DEFAULT která obsahuje nějaký početní výraz musí být uzavřená v závorkách (ikdyž je to jedna funkce). (To se týká poslední DEFAULT podmínky v následujícím příkladě.)
SQLite nerozumí klíčovému slovu DEFAULT při INSERTu (nebo UPDATu):
Error: near "DEFAULT": syntax error
sqlite> INSERT INTO sladky_rohlik(pocet) VALUES(100);
sqlite> select * FROM sladky_rohlik;
zavoznik pocet dovezeno spotrebovat_do
--------------- ---------- ---------- --------------
Tomáš Tlustý 100 2013-11-28 2013-12-03
K zobrazení indexů z tabulky se používá metapříkaz .indices:
sqlite_autoindex_zapis_1
Neukončujte metapříkaz .indices středníkem, SQLite by si myslelo že je součást názvu tabulky.
K mazání indexů se používá DROP INDEX, ale nelze smazat index svázaný
s integritním omezením UNIQUE (nebo primarním klíčem):
Oracle
U Oracle Database moc rozdílů tentokrát není.
První drobností je, že DROP TABLE nemá
část IF EXISTS.
Jak si s tím poradit ukáži příště.
V Oracle neexistuje datový typ TEXT, místo něj
použijte CLOB. A také byste všude
měli používat datový typ VARCHAR2
místo VARCHAR, který je zastaralý.
Hlavním překvápkem je nemožnost použití current_date
v podmínce CHECK. Oracle fylozofie je totiž taková,
že podmínka CHECK musí pro data v tabulce být neustále pravdivá.
Jenže když dáte do podmínky, že musí být datum větší než
„dnešní“ datum, tak vložená hodnota může dnes podmínce
vyhovět, ale za týden už ne.
Je to vcelku logický a správný požadavek, jen pro nás uživatele je to trošku pruda. Řešení sice existuje (TRIGGERY mohou automaticky vkládat do sloupečků hodnotu aktuálního času (resp. jakoukoliv hodnotu)), ale triggery jsou zatím nad rámec tohoto kurzu.
Vypsání indexů tabulky taky není v Oracle žádný med.
Dá se to udělat následujícím SQL příkazem, který zatím nebudu
vysvětlovat a vy se jej nesnažte pochopit (na JOIN
příjde řada v některé z dalších kapitol).
user_ind_columns.column_name
FROM user_tables
JOIN user_indexes on user_indexes.table_name = user_tables.table_name
JOIN user_ind_columns ON user_indexes.index_name = user_ind_columns.index_name
WHERE user_tables.table_name = 'ZAPIS'
ORDER BY user_tables.table_name,user_indexes.index_name;
Všimněte si, že jméno tabulky zapis je v podmínce WHERE
zapsáno velkými písmeny.
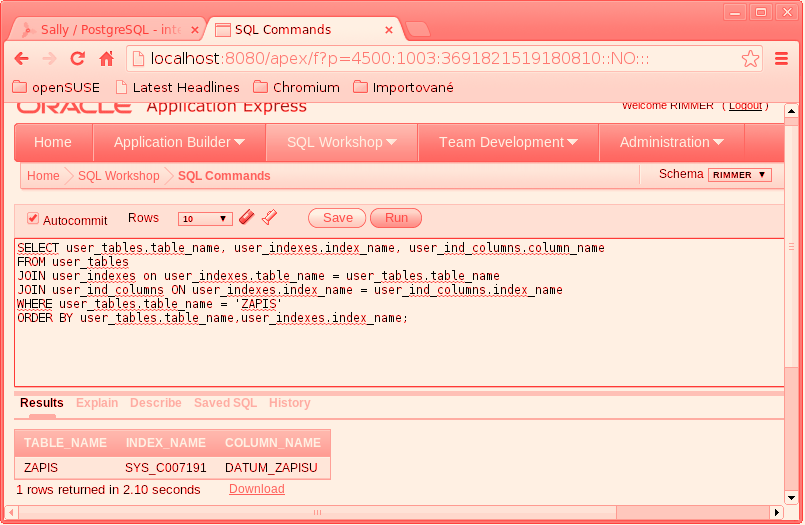
Zobrazení indexu v Oracle
Indexy mají platnost v rámci schématu, takže jejich mazání je stejné jako v PostgreSQL. A taky platí, že index pro UNIQUE omezení ani primární klíč nemůžete smazat (můžete odstranit podmínku UNIQUE nebo primární klíč a tím smazat i index, ale o tom zase až později).
Oracle interně převádí prázdný řetězec '' na hodnotu NULL.
Lze sice definovat sloupec takto:
Ale protože se '' převádí na NULL, nemůže se defaultní hodnota
u NOT NULL sloupečku '' nikdy použít, čili je na prd.
Nemůžete ani INSERTnout ''. Takže se v Oracle u textových sloupečků (CHAR,
VARCHAR2, CLOB) podmínce NOT NULL raději vyhněte.
Oracle je přecitlivělý na pořadí integritních pomínek a defaultních hodnot. Takže:
