

Začínáme s PostgreSQL
V této kapitole se dozvíte jak vytvořit databázi (schéma), jak získat nápovědu, něco o metapříkazech, znakových sadách a dumpování obsahu databáze do textového souboru (souboru SQL příkazů).
Databáze
Nyní se podíváte na to, jak vytvořit a smazat databázi, tj. nějaké soubory, ve kterých budou uloženy data. V jakém souboru to konkrétně bude (jak se jmenuje a kde je uložen) není důležité. O to se stará server.
Ukáži použití klienta psql pro připojení k databázi a představím jednu
psql vychytávku – metapříkazy.
Dozvíte se teké, jak data z databáze „vydumpovat“ do textového souboru ve formě SQL příkazů a jak data zase zpět do databáze nahrát.
Vytvoření databáze
Chcete-li pracovat s databází, musíte jí nejdříve vytvořit. K tomu potřebujete mít příslušná práva – musíte být uživatelem s právem CEATEDB. To jsem ukazoval v kapitole o instalaci. Nyní si na zkoušku můžete vytvořit databázi se jménem rimmer1.
Zadejte příkaz v příkazové řádce:
CREATE DATABASE
Pokud proběhne vytvoření databáze úspěšně, zobrazí se zpráva CREATE DATABASE (ale taky nemusí, záleží na nastavení). Pokud databáze se stejným jménem již existuje, budete na to upozorněni (původní, již existující databáze se nepřemaže).
Jméno databáze můžete zvolit stejné, jako je vaše přihlašovací jméno (login) v Linuxu.
Pokud spustíte psql bez zadání názvu databáze, pokusí se připojit k databázi se
stejným jménem jako je váš login.
Já jsem přidal ke jménu databáze na konec jedničku, aby bylo na první pohled jasné,
zda mluvím o databázi nebo o loginu uživatele.
Databázi můžete vytvořit i v psql clientovi (dále už budu psát jen psql a
budu tím myslet jakéhokoliv klienta pro spojení s Postgresem) následujícím
SQL příkazem (začínajícím za =>). Všimněte si středníku na konci příkazu:
CREATE DATABASE
psql zvyk,
že tím oznamuje úspěch provedené akce. Při neúspěchu vypíšě chybu.
V zájmu stručnosti a přehlednosti nebudu vždycky vypisovat co klient po provedení úsěšného příkazu vrací.
- TEMPLATE
-
určuje, jakou databázi použít jako šablonu pro vytvoření nové. Pokud nic nezadáte, vytvoří se databáze podle databáze
template1. Ta v sobě obsahuje nějaké, pro nás aktuálně nezajímavé, databázové objekty. Pokud jsou tyto objekty v jiném kódování, než ve kterém je nově vytvářená databáze, tak se vytvoření databáze nezdaří.Používejte jako šablonu
template0. Ta neobsahuje nic, takže s ní problémy nehrozí. - ENCODING
-
určuje znakovou sadu, v jaké se budou ukládat texty v databázi. Asi víte, že existují různé znakové sady (UTF-8, Windows-1250, ISO-8859-2 atd.). Znaková sada určuje, pod jakými čísly se znaky ukládají a kolik budou zabírat místa. Některé znakové sady zabírají více místa a umožňují používat znaky z mnoha jazyků (písmena s háčkami, čárkami, přehláskami, čínské čmáranice …), což je třeba příklad UTF-8, některé používají méně bytů, ale zase mají jen omezený repertoár znaků (například Windows CP1250 je kódování pro středoevropské jazyky od firmy Windows, zatímco ISO-8859-2 je taktéž kódování pro středoevropské jazyky, ale tentokrát se jedná o standard (který používal Linux)).
Používejte kódování UTF-8. Možná by se vám mohlo ve Windows lépe pracovat s WIN1250, ale UTF-8 je prostě modernější a poradí si s většinou jazyků, se kterými se můžete setkat.
- LC_COLLATE
- určuje, jak se budou znaky řadit. Čeština má například tu specialitu, že
chje v abecedě předcd, protožechse bere jako jedno písmeno.Používejte pro COLLATE cs_CZ.UTF-8, pokud je to možné (a vhodné).
Postgres umí „tradiční C“ COLLATE (normální řazení a-z), které se jmenuje
Ca pakPOSIX(to je nějaká norma). Další podpora COLLATE je závislá na operačním systému, takže se může taky stát, žecs_CZ.UTF-8nebudete mít dostupné. - LC_CTYPE
-
určuje další informace o znacích (např. co je znak, co je číslo, co je velké a co malé písmeno atd.).
LC_CTYPE byste ani nemuseli zadávat, ono se k LC_COLLATE vybere tak nějak samo to správné.
SQL příkaz na vytvoření databáze by se dal zapsat také takto:
Mezery (nebo nové řádky) nehrají roli. Slovíčko WITH, stejně jako rovnítka, je nepovinné (je jedno, jestli je uvedete nebo ne).
Při vytváření databáze se dají určit ještě další informace, o kterých jsem se nezmínil. Podívejte se do dokumentace. To, co je v hranatých závorkách, je nepovinné. Buď je to tam na okrasu nebo aby se splnil nějaký SQL standard a prakticky nemá žádný význam (to je případ slovíčka WITH), nebo se při vynechání použije nějaká defaultní hodnota (to je případ TEMPLATE, ENCODING, LC_COLLATE i LC_CTYPE).
Zrušení databáze
Pokud zrušíte databázi, už se to nedá vzít zpět. Zrušením databáze smažete všechny tabulky, které jste v ní vytvořili! To vás ale zatím nemusí trápit, protože jste žádnou tabulku nevytvořili :-).
Smazat databázi můžete z příkazové řádky programem dropdb.
A ještě jak se to dá udělat v klientovi:
V žádném případě nemažte databázi kterou jste nevytvořili, pokud si nejste jisti že víte co děláte. Postgres při své instalaci vytvoří několik databází, které potřebuje pro svůj běh!
Komunikace s databází
Pro komunikaci s databází postgres slouží program psql. Jedná se o textového klienta, který doporučuji používat.
V předchozí kapitole jsem vysvětlil, že program postgresql je serverem a
psql klientem. Pokud se chcete připojit k databázi, musíte říci k
jaké. Vytvořte databázi rimmer1 a připojte se k ní:
CREATE DATABASE
$ psql rimmer1
Welcome to psql, the PostgreSQL interactive terminal.
Type: \copyright for distribution terms
\h for help with SQL commands
\? for help on internal slash commands
\g or terminate with semicolon to execute query
\q to quit
rimmer1=>
V příkazové řádce ve Windows před spuštěním psql
zadejte tento příkaz: chcp 1250.
Takto změníte codepage příkazové řádky na windows 1250,
které využívá i psql. (Defaultní codepage příkazové
řádky ve Windows je cp852.)
Nyní jsou očekávány vaše (SQL) příkazy. Krom toho můžete také zadávat
metapříkazy. To jsou příkazy které začínají zpětným lomítkem
a většinou mají jen nějaký informativní charakter
(třeba \h zobrazí nápovědu).
Pomocí šipky nahoru (na klávesnici) si můžte procházet historii příkazů, příkazy
upravit (opravit) a spustit znovu (nejsem si jistý, jestli to tak funguje i ve Windows).
Práci s databází ukončíte metapříkazem \q.
Všechny příkazy se spouští klávesou Enter.
Všechny SQL příkazy se ukončují středníkem (a pak se Enterem spustí).
Metapříkaz \q ukončí program psql.
$
Klienta psql můžete ukončit i kombinací kláves CTRL+d v Linuxu, v DOSu a
Windows je to CTRL+z a Enter.
Metapříkazy
Metapříkazy ještě nejsou příkazy SQL a v jiných SQL programech
než je Postgres nemusí vůbec existovat (ani v jiných postgres klientech,
než je psql).
Metapříkazy začínají zpětným lomítkem a neukončují se (na rozdíl od SQL příkazů) středníkem.
Dva metapříkazy jste si již mohli
vyzkoušet – příkaz na ukončení sezení \q a příkaz
zobrazující stručnou nápovědu \h. Další metapříkazy,
které by se vám mohly v krátké době hodit, jsou následují:
- \q
-
Ukončí program
psql. - \h
-
Tento metapříkaz budete pravděpodobně využívat nejčastěji. Pokud jej
zadáte bez argumentu, vypíše vám všechny možné příkazy SQL.
Jako argument můžete zadat jeden z SQL příkazů. Pak se vám ukáže krátký
popis toho co příkaz dělá, spolu se syntaxí příkazu.
Nedozvíte se žádné podrobnosti jako v nápovědě na webu, spíš vám pomůže si vzpomenout, co všechno příkaz umí.Tak například:
Dočtete se, že příkaz DROP DATABASE slouží k odstranění databáze. To co vidíte v syntaxi příkazu velkými písmeny se nemění. Vždy tedy píšete úvodní slova DROP DATABASE. To co je v hranatých závorkách [ ] je nepovinné – IF EXISTS může a nemusí být součástí SQL příkazu (pokud jej chcete použít, tak se píše bez hranatých závorek).
Za výrazy s malými písmeny se dosadí příslušná hodnota (místo jméno byste měli dosasit skutečné jméno databáze, kterou chcete smazat.Další příklad:
rimmer1=>\h END
Command: END
Description: commit the current transaction
Syntax:
END [ WORK | TRANSACTION ]Znak
|(svislítko) znamená „nebo“. Příkaz END může mít jeden, nebo žádný argument (argumenty jsou v hranatých závorkách). Argument může být WORK nebo TRANSACTION.Pokud by místo hranatých závorek [] byli špičaté {}, znamnalo by to, že musí být jeden z argumentů uveden, tj. že příkaz musí mít jeden z vyjmenovaných argumentů.
A další příklad:
rimmer1=> \h drop table
Command: DROP TABLE
Description: remove a table
Syntax:
DROP TABLE [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]A tady si všiměte
name [, ...]. Tím se nám nápověda snaží naznačit, že můžete uvést více než jedno jméno tabulky (oddělená čárkou).Tyto příklady jsem uvedl, abyste lépe porozuměli nápovědě. Vlastní význam příkazů proberu v některé z dalších kapitol.
- \?
-
Tento metapříkaz vypíše všechny možné metapříkazy.
Pokud se výstup nevejde na obrazovku, můžete se ve výpisu pohybovat klávesou ENTER, mezerníkem a šipkami. Prohlížení ukončíte klávesouq. - \l
-
(Malé L) Vypíše tabulku všech existujících databází.
rimmer1=>\l
Seznam databází
Jméno | Vlastník | Kódování | Collation | CType | Přístupová práva
-----------+----------+----------+-------------+-------------+-----------------------
petr | petr | UTF8 | cs_CZ.UTF-8 | cs_CZ.UTF-8 |
postgres | postgres | UTF8 | cs_CZ.UTF-8 | cs_CZ.UTF-8 |
rimmer1 | petr | UTF8 | cs_CZ.UTF-8 | cs_CZ.UTF-8 |
template0 | postgres | UTF8 | cs_CZ.UTF-8 | cs_CZ.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | cs_CZ.UTF-8 | cs_CZ.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(5 řádek)
- \d
-
Tento metapříkaz vám ukáže všechny objekty, které v databázi máte. Nyní tam nemáte nic, takže se vám ukáže, že se vám nemá co ukázat. Ukážeme si to na příkladu.
Abychom si měli co ukázat, vytvoříme si tabulku, která bude mít dva sloupce, v jednom bude text, ve druhém číslo. (Hurá, náš první SQL příkaz – ale zatím jej nechám bez hlubšího vysvětlení).
rimmer1=> CREATE TABLE pokus (text text, cislo integer);
CREATE TABLE
rimmer1=> \d
Seznam relací
Schéma | Jméno | Typ | Vlastník
--------+-------+---------+----------
public | pokus | tabulka | petrMetapříkaz \d může mít argument, kterým bude „objekt“, který máte v databázi. Objektem je například tabulka (o dalších typech objektů, co můžete mit v databází, se dozvíte později).
rimmer1=> \d pokus
Tabulka "public.pokus"
Sloupec | Typ | Modifikátory
---------+---------+--------------
text | text |
cislo | integer |
rimmer1=> DROP TABLE pokus;Jak vaše databáze poroste a bude obsahovat více a více objektů, budete chtít vypsat například jen tabulky. K tomu slouží několik „bratříčků“ metapříkazu
\d; Například\dtvypíše jen tabulky.
Nemá cenu abych tyto bratříčky vypisoval, když ještě nevíte, jaké objekty můžete v databázi mít. Až se k jednotlivým objektům dostanu, zmíním se i o příslušném metapříkazu. Ostatně, pomocí\?tyto metapříkazy už umíte zjistit sami. - \dO
-
(\d a velé o) Vypíše všechna COLLATION, která máte k dispozici.
Že vám
\dOnic nevypíše? No to je tím, že ve své databázi žádné definované nemáte. Pokud chcete vidět ty systémové, musíte doplnit metapříkaz písmenkemS:rimmer=> \dOS
Seznam collations
Schéma | Jméno | Collation | CType
------------+------------------+------------------+------------------
pg_catalog | C | C | C
pg_catalog | POSIX | POSIX | POSIX
pg_catalog | aa_DJ | aa_DJ.utf8 | aa_DJ.utf8
pg_catalog | aa_DJ.utf8 | aa_DJ.utf8 | aa_DJ.utf8
...
pg_catalog | cs_CZ | cs_CZ.utf8 | cs_CZ.utf8
pg_catalog | cs_CZ.utf8 | cs_CZ.utf8 | cs_CZ.utf8
...
(426 řádek)Spousta metapříkazů existuje ve verzi s
Sna konci pro vypsání systémových informací.
Dávkové soubory (dump databáze)
Příkazy SQL také můžete zapsat do souboru ve stejné formě, jako byste je zadávali na příkazovou řádku (i se středníkem na konci SQL příkazů). Poté je na databázi aplikujete takto:
Soubor je obyčejný textový soubor a na jeho koncovce vůbec nezáleží. Někdy se mu nadává dávkový soubor, protože obvykle obsahuje nějakou dávku SQL příkazů (kvůli jednomu příkazu by se ho asi nevyplatilo psát).
Pokud do dávkového souboru chcete přidat nějaký komentář, uveďte na začátku
řádky s komentářem
-- (dvě mínus a mezeru) a vše další až do konce řádky bude ignorováno.
Chcete-li naopak data z databáze uložit do souboru (ve formě
SQL příkazů), použijte k tomu program pg_dump.
Můžete si to vyzkoušet, ale protože teď v databázi nic nemáte, nic smysluplného se vám nevydumpuje.
Vydumpované soubory obvykle obsahují spoustu nestandardních věcí, které znemožňují vzít skript z jedhoho DBMS a nahrát ho do jiného DBMS. Pro začátek vám poradím toto: cokoliv se vydumpuje a vy tomu nerozumíte smažte :-).
MySQL/MariaDB
Rozdíly v dalších databázích se budu snažit popisovat velmi stručně, takže bez dalšího zdržování uvedu rovnou příklad na vytvoření a smazání databáze v MySQL:
Všimněte si slova DEFAULT. Znaková sada a COLLATE se v MySQL definuje na úrovni tabulky a ne databáze. Tímto jen definujete, jaká znaková sada a COLLATE se má použít jako defaultní, tedy u nově vytvářené tabulky, u které znakovou sadu nebo COLLATE nedefinujete explicitně.
Schizofrenie v názvosloví je krásně vidět na tom, že místo DATABASE můžete
v obou příklade psát SCHEMA a bude to znamenat to samé.
A já vám doporučuji používat
název SCHEMA, protože je jasnější o čem je řeč, než používání všehobjímající slovo DATABASE.
V MySQL také existují metapříkazy, ale jsou velice odlišné. Třeba metapříkaz \h
nezobrazí přehled SQL příkazů, ale přehled metapříkazů (kterých je o poznání méně než v psql).
Pokud se chcete dostat k nápovědě k SQL dotazům, použijte příkaz
help,
pak help contents,
pak třeba help Data Definition a
nakonec help CREATE DATABASE.
Name: 'CREATE DATABASE'
Description:
Syntax:
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification] ...
create_specification:
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
CREATE DATABASE creates a database with the given name. To use this
statement, you need the CREATE privilege for the database. CREATE
SCHEMA is a synonym for CREATE DATABASE.
URL: http://dev.mysql.com/doc/refman/5.6/en/create-database.html
Příkaz mysqldump vydumpuje databázi:
SQLite
Program sqlite3 při spuštění očekává jako argument
název souboru, se kterým bude pracovat jako s databází. Pokud
soubor neexistuje, vytvoří jej. Pokud existuje, ověří, že se jedná
o platný SQLite soubor a pracuje s ním.
SQLite umí pracovat jen s UTF-8 a UTF-16 kódováním. To první je defaultní, bez toho druhého se (zatím) obejdete.
Příkaz pro nápověda v programu sqlite3 je .help
(i s tou tečkou na začátku).
Další zajímavé metapříkazy jsou .headers ON
a .mode column, které
vám doporučuji vždy spouštět. Zajistí hezčí výpis při výpisu obsahu tabulky.
Metapříkaz .tables vypíše všechny tabulky.
.headers ON a .mode column do souboru ~/.sqliterc
a nebudete je muset psát po každém spuštění sqlite3
Metapříkaz .dump vydumpuje databázi.
Oracle
Oracle vám vytvoří databázi rovnou při vytvoření uživatele (jak jsem ukazoval v části o instalaci). Defaultní kódování je UTF-8.
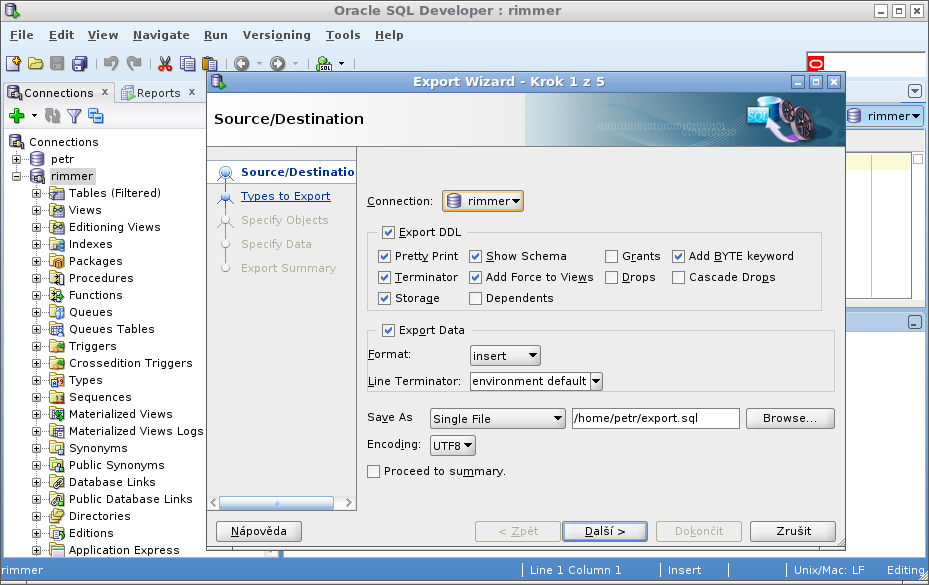
Oracle Export
Dumpování databáze můžete udělat přes
Oracle SQL Developer (Tools → Database Export… spustí
Export Wizard, kde si všechno naklikáte).
Apex bohužel nemá nic vhodného na dumpování.
Můžete si přes něj vydumpovat tabulku po tabulce v CSV formátu, můžete
si zobrazit CREATE TABLE příkazy pro jednotlivé tabulky, ale nevydumpujete si
celé schéma najednou.
Apex nabízí jen možnost nahrát SQL skripty (SQL Workshop → SQL Scripts → Upoad >) a nahrané skripty spustit (případně i upravit).
Apex i SQL Workshop mají limit, který omezuje velikost skriptu, který je možný nahrát. V případě nouze tak můžete využít pro nahrání velkého skriptu příkazový řádek:
$ . ./bin/oracle_env.sh # nastaveni prostredi
$ ./bin/sqlplus jmeno/heslo < script.sql # nahrani skriptu pomoci programu sqlplus
